


When & Why Service Discovery in Microservices?
Suppose the service you're working on uses synchronous Remote Procedure Invocation (RPI) to invoke another service of your application - e.g., REST API and your service code need to know the network location (IP and port) of the destination service instance.
Traditional applications run on physical hardware wherein the services have static network locations, therefore the client service can store and read these locations in and from a configuration file/database that's updated only occasionally. Modern, cloud-based service instances, however, have dynamically assigned network locations. Additionally, the set of service instances can change dynamically due to autoscaling, upgrades, or failures.
Therefore, a dynamic mechanism to route client requests to the appropriate destination services is needed - Service Discovery.
Service Discovery Patterns
Two Components in Service Discovery
- Service Registry: a database of network locations of application's service instances.
- Service Discovery Mechanism that takes care of:
- updating the Service Registry when service instances start and stop, and
- querying the Service Registry to obtain a list of available service instances when needed.
Implementing Service Discovery
There are two ways of implementing Service Discovery based on where the Service Discovery Mechanism is implemented:
Application-level Service Discovery - Service Discovery Mechanism is with the services
- The application's services and their clients interact with the Service Registry directly.
- This means:
- A service registers its network location with the Service Registry.
- A client service invokes a service by first querying the Service Registry.
- The Service Registry returns all the instances of the service available - the client service needs to take care of load balancing as well.
Generally, service discovery client libraries come with load balancer capabilities; Eureka Client comes with Spring Cloud Load Balancer, for instance. The following figure shows an overview of how the Application-level Service Discovery roughly looks like with an example of an application with few services and an API gateway:
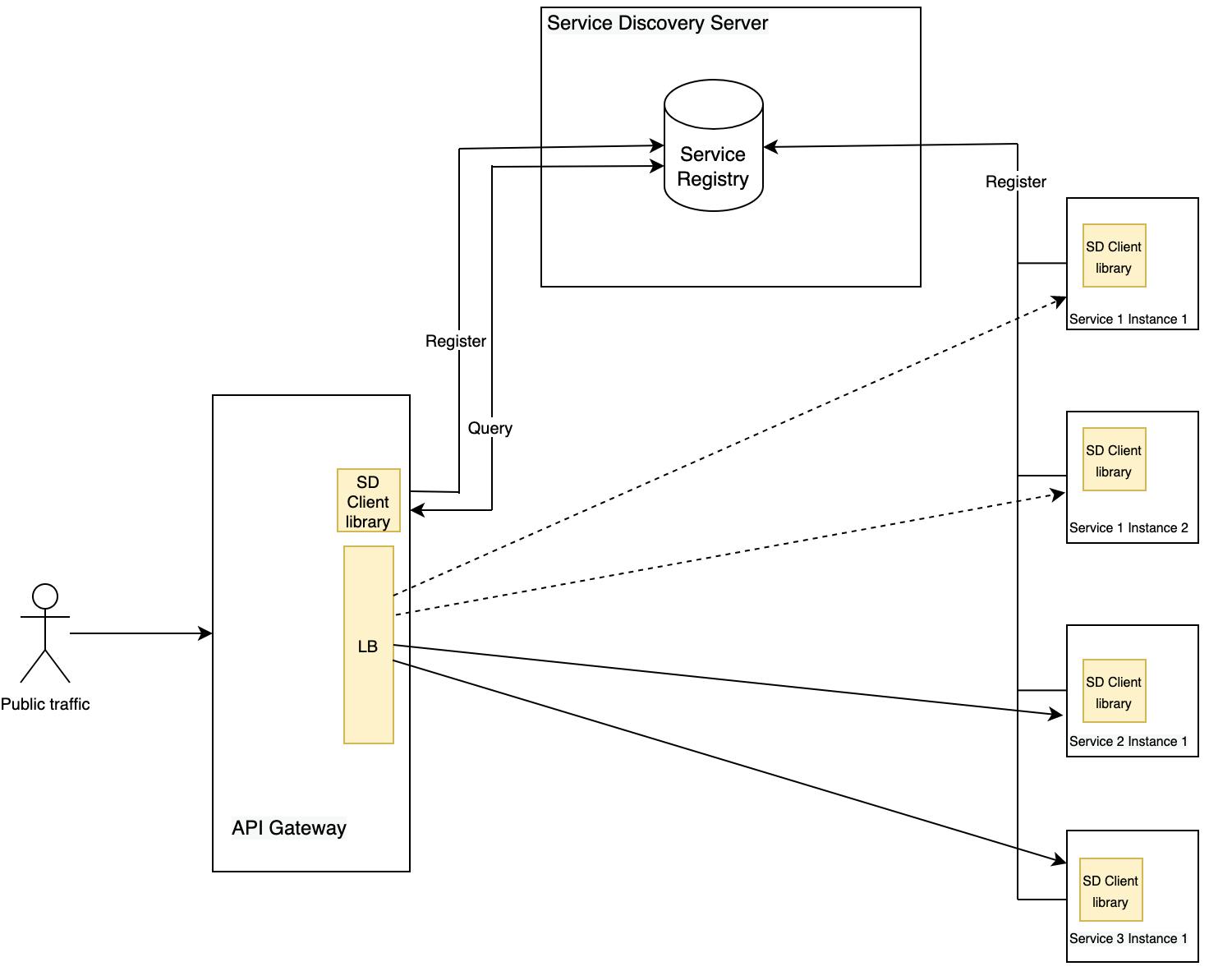
- To summarize, this Service Discovery approach uses the following two patterns in combination to implement the Service Discovery Mechanism:
- Self-registration Pattern
- A service instance registers its network location by invoking the Service Registry's API.
- The service instance either supplies the Service Discovery server with a health check URL that the discovery server will invoke periodically to ascertain that it can handle client requests, or
- The Service Discovery server will need the service instances to ping its heartbeat API periodically to preserve their registration.
- Client-side Discovery Pattern
- When a client service wants to invoke another service, it first queries the Service Registry to obtain a list of available service instances.
- The client service might cache the service instances for improved performance.
- It then uses a load balancing algorithm, such as round-robin or random to select a service instance to which the request is finally sent.
- Self-registration Pattern
Deployment platform-provided Service Discovery - Service Discovery Mechanism is handled by the deployment infrastructure
- Modern deployment platforms such as Docker and K8s have a built-in Service Registry and a Service Discovery Mechanism.
- The deployment platform assigns each service a DNS name and a Virtual IP (VIP) address - the DNS name resolves to the VIP address.
- Client services make requests to the DNS name which eventually resolves to the VIP address, the deployment platform takes care of routing a request to one of the available instances of the destination service.
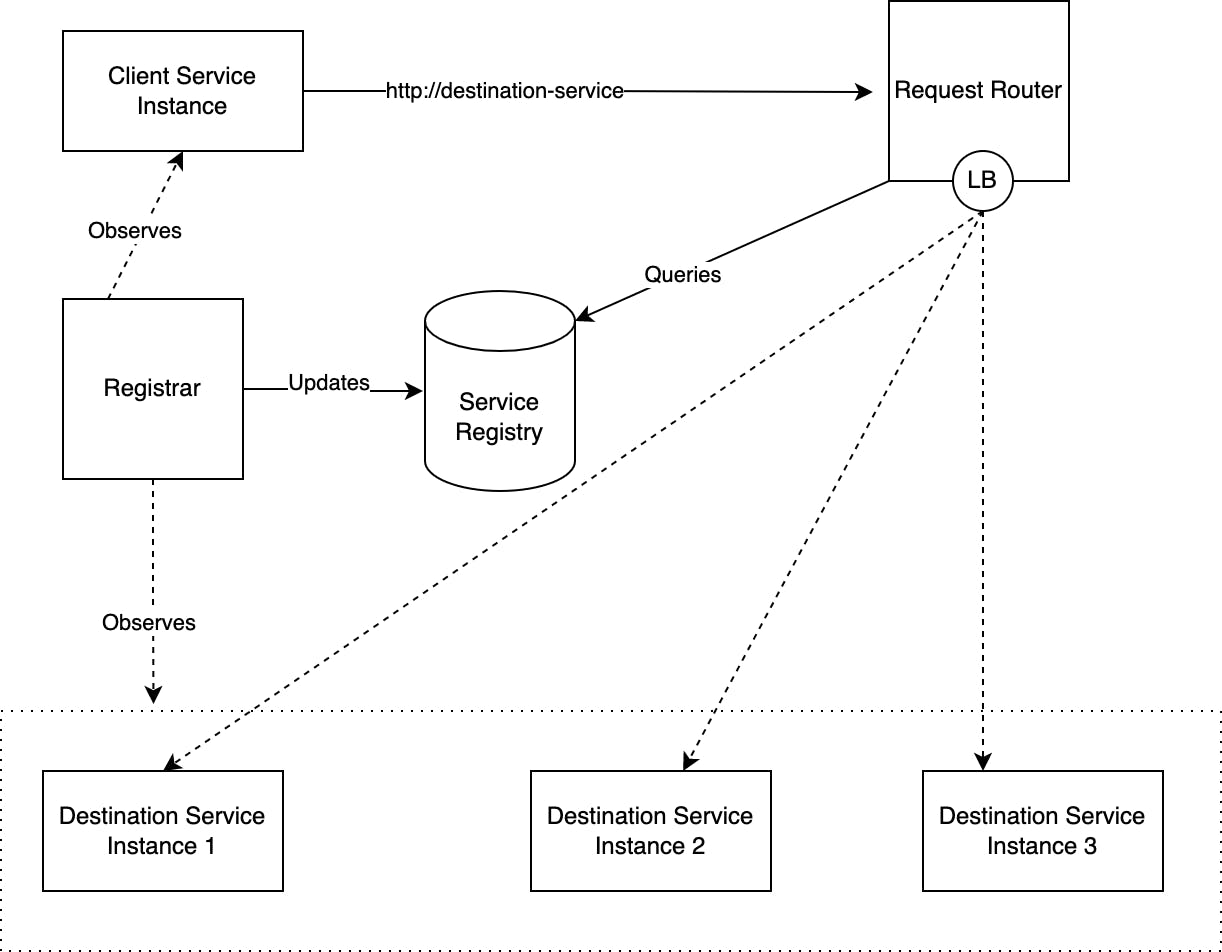
- The Deployment platform-provided Service Discovery Mechanism uses the following
two patterns in combination:
- Third-party registration pattern
- Instead of the services themselves registering with the Service Registry, a third party called the Registrar handles service registration.
- The Registrar is typically a part of the deployment platform.
- Server-side Discovery Pattern
- Instead of the client services querying the Service Registry directly, they make requests to the DNS name of the destination service which is handled by a Request Router that queries the Service Registry and load balances the requests.
- Third-party registration pattern
- The following figure roughly represents the Platform-provided Service Discovery Mechanism:
Advantages and Disadvantages of the two Implementation Patterns
Application-level Service Discovery
| Advantages | Disadvantages |
| The Service Discovery Mechanism handles the scenario when services are deployed in different deployment environments. E.g.- when some services are deployed in K8s, while others are running in legacy environments, the services can still register with the Eureka Service Registry. | We would need a service discovery client library for every language and framework that we might be using across our services. |
| Operational responsibilities for setting up and managing the Service Discovery (Registry + Mechanism) which can be a distraction. |
Platform-provided Service Discovery
| Advantages | Disadvantages |
| Both Service Registry, as well as Mechanism, are handled by the deployment platform. | This mechanism can support service discovery for only those services that are deployed on the platform. E.g.- K8s-based service discovery will work only for services deployed on K8s. |
| This mechanism is completely independent of the language/framework in which the services might be written - none contain any service discovery code. |
Which one's better?
Like most of the questions in Software Engineering, the answer to this question is also the same - "It depends.".
However, it's often suggested to prefer Platform-provided Service Discovery over Application-level Service Discovery whenever possible.
Sample code for Application-level Service Discovery
You can have a look at how Application-level Service Discovery works with these code samples - github.com/krishnakrmahto/sample-projects-s...